深度学习系列第一篇 — 入门
这篇文章是学习人工智能的笔记,首先抛出下面一个问题。
人工智能、机器学习和深度学习之间的关系?
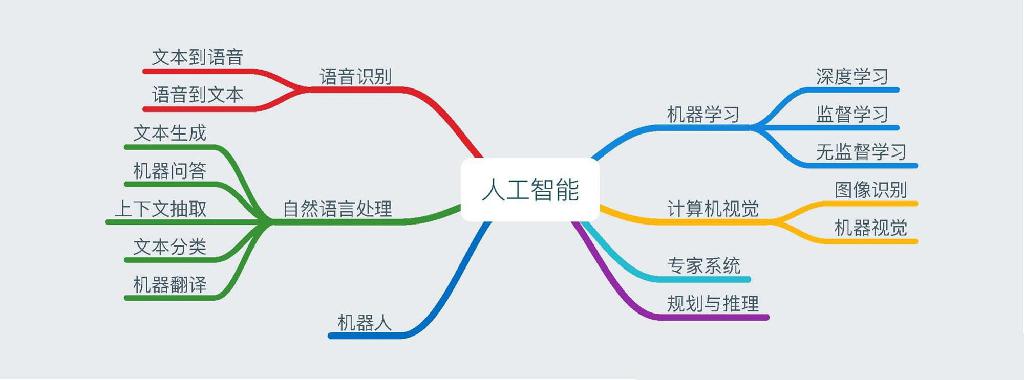
从图中可以看出人工智能概念的范围更广,机器学习是其中的一个子集,而深度学习又是机器学习中的一个子集。
深度学习的应用领域在计算机视觉、语音识别、自然语言处理和人机博弈方面比基于数理统计的机器学习会有更高的准确度。这里主要是做深度学习方面的学习笔记。
深度学习的发展历程
深度发学习是深度神经网络的代名词,其起源于上世纪,只是在这几年开始火起来。
早期的神经网络模型类似于放生机器学习,由人类大脑的神经元演化出的神经元模型,见下图(图摘自《TensorFlow 实战Google深度学习框架》):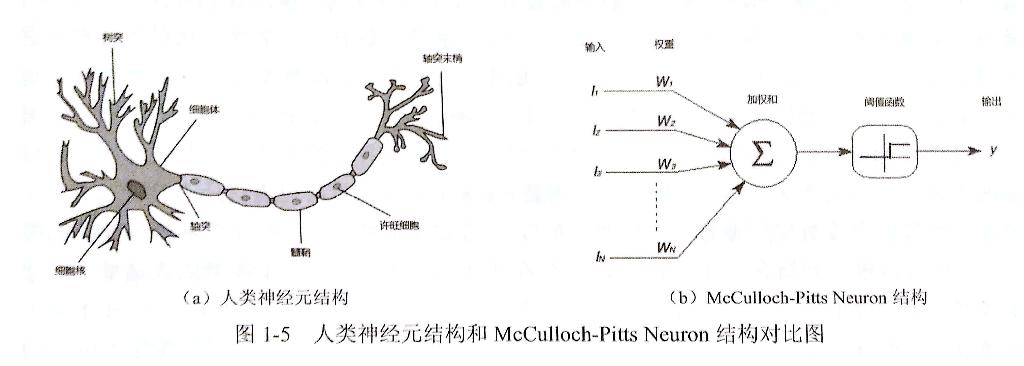
后面出现了感知机模型、分布式知识表达和神经网络反向传播算法,再到后来的卷积神经网络、循环神经网络和 LSTM 模型。
在神经网络发展的同时,传统机器学习算法的研究也在不断发展,上世纪 90 年代末逐步超越了神经网络,在当时相比之下传统机器学习算法有更好的识别准确率,而神经网络由于数据量和计算能力的限制发展比较困难。到了最近几年,由于云计算、GPU、大数据等的出现,为神经网络的发展做好了铺垫,AI 开始了一个新的时代。从自身出发,高中设立的一个比较模糊的梦想是参与到人工智能的研发当中去,所以大学学了计算机,当梦想与时代的发展有了一个交点,梦想的实现变得更加触手可及。
下面一张图表是对比主流深度学习开源工具(图摘自《TensorFlow 实战Google深度学习框架》)
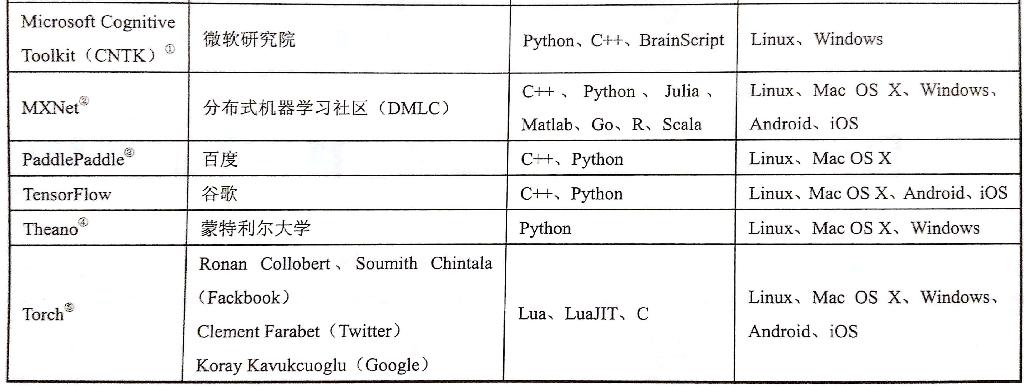
目前我听说的比较多的两个开源工具是 Caffe 和 TensorFlow,然后去看了下 Github 关注量,前者 20.1k 后者 69.3k,TensorFlow 应该是目前最火的一个深度学习框架了吧。这篇文章包括后面的文章都会去记录 TensorFlow 的学习过程,下面的内容是介绍 TensorFlow 的基础概念,介绍中我尽量避免加入代码,因为目前 TensorFlow 更新比较快,发现好多写法在新的版本中不再被支持。
TensorFlow 学起来
TensorFlow 有两个重要概念 Tensor (张量)和 Flow(流),Tensor 表名的是数据结构,Flow 提现的是计算模型。
PS:以下将 TensorFlow 简称为 tf
tf 计算模型 — 计算图
tf 通过计算图来表述计算的编程系统,其中的每个节点表示一个计算,不同点之间的连接表达依赖关系。下面几行代码表达一下:
1 | import tensorflow as tf |
上面的代码在计算图中会有 a、b、a + b三个节点。tf 默认会有一个全局的计算图,也可以生成新的计算图,不同计算图之间不会共享张量和运算。
计算图中可以通过集合的方式管理不同的资源,这些资源可以是张量、变量或者队列资源等。
tf 数据模型 — 张量
张量是 tf 管理和表示数据的形式,可以简单理解为多维数组。零阶张量表示标量,就是一个数;一阶张量是一个一维数组;n 阶张量是一个 n 维数组。 tf.add(a, b, name='add') 这行代码在运行时并不会得到结果,而是一个结果的引用,是一个张量的结构,包含三个属性 name、shape、dtype,name 仅仅是一个节点的名称;shape 是张量的维度,这个是一维的,长度为 2,这个属性比较重要;dtype 是数据类型,每个张量有唯一的数据类型,不同张量之间的计算需要保证类型统一。
上面的例子就是对两个常量做加法,然后生成计算结果的引用。
tf 运行模型 — 会话
tf 的会话用来执行定义好的运算,会话用来管理运行过程中的所有资源,计算完成后会帮助回收资源,通过 with tf.Session() as sess: 这种方式会在 with 结束时自动关闭回收资源。
通过 tf.ConfigProto 可以配置类似并行线程数、GPU分配策略、运算超时时间等参数,将配置添加到 tf.Session 中创建会话。
向前传播算法
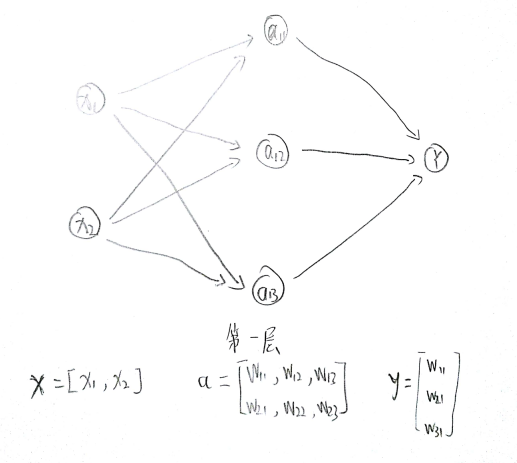
通过全连接网络结构介绍,一个神经元有多个输入和一个输出,输出是不同输入的加权和,不同的输入权重就是神经网络的参数,神经网络的优化就是优化参数取值的过程。全连接网络结构是指相邻两层之间任意两个节点之间都有连接。
向前传播算法需要的三部分信息:
- 第一部分从实体中取出特征向量作为输入。
- 第二部分是神经网络的连接结构,不同神经元之间的输入输出的连接关系。
- 第三部分是每个神经元中的参数。
在 tf 中通过变量(tf.Variable)来保存和更新神经网络中的参数。
1 | import tensorflow as tf |
[[ 3.95757794]]