Xpath总结
- Firefox + Firepath、Chrome + XPath Helper
- 常用xpath例子
- Python 使用XPath匹配页面数据
- 参考
Firefox + Firepath、Chrome + XPath Helper
如下图 Firefox下,XPath需要通过Firebug + Firepath来方便的获取。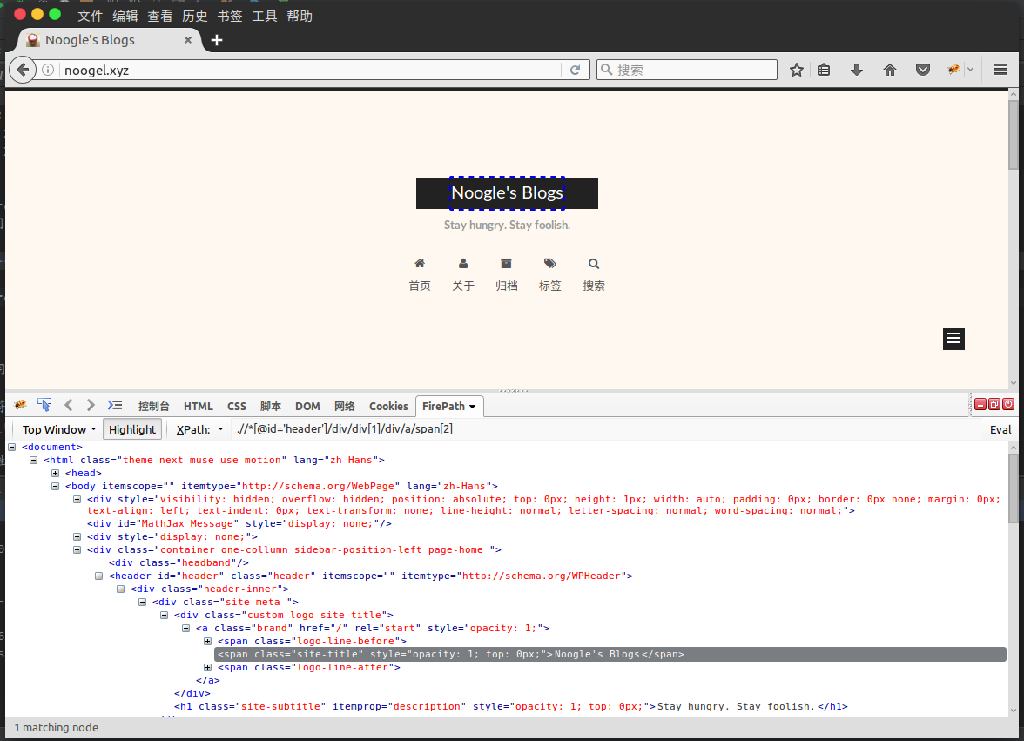
Chrome下,通过XPath Helper插件实现,开启和关闭快捷键Ctrl + Shift + X,按住Shift键获取。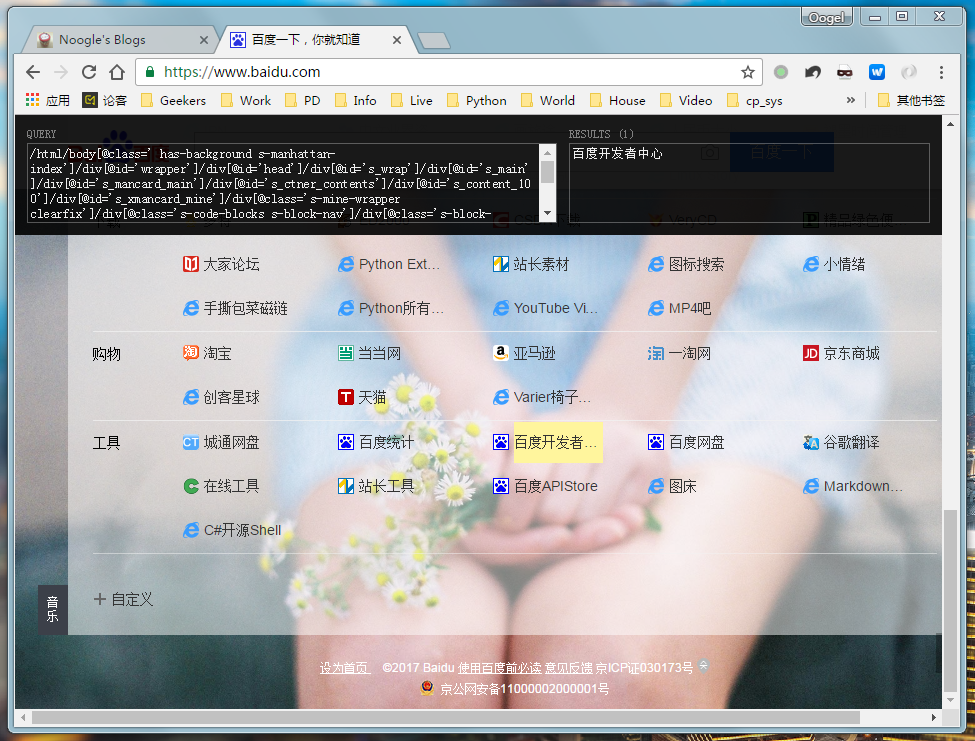
以上两种方式还是Firefox下使用比较方便,更多用法自行发掘。
常用xpath例子
根据字符串匹配节点,通过contains()、text()匹配.//*[@id='detail_all']/div[1]/ul/li[contains(text(), '字 数:')]/text()
节点属性不包含**字符串,通过not()、contains()匹配.//*[@id='con_ListStyleTab4A_1']/p[not(contains(@class, 'title'))]/a[@class='Author']/text()
截取字符串匹配substring-before(//div[@class='content']/ul/li[6],',')substring(.//h2/../p/span[contains(text(), '字数:')]/text(), '4')
索引匹配末尾节点,通过last()匹配.//div[last()]/div[@class='show_info_right max_width']/text()
通过..向上级查找匹配.//h1/../div[@class='booksub']/span/span/text()
获取过个节点下的内容,通过//node()/text()可以获取当前节点及其子节点的内容。.//*[@id='job_detail']/dd[@class='job-advantage']//node()/text()
有的时候页面中一系列数据下面并不一定包含某些字段,这时我们通过contains()来匹配包含某些关键字的节点来寻找对应的另一个节点。.//div[@class='infobox']//node()[contains(text(), '户型')]/../node()/text()
这里总结一点使用技巧,更多的关于XPath的方法可以看参考中的链接,足以解决大部分问题。
Python 使用XPath匹配页面数据
对于爬虫抓取中XPath是一种比较高效的获取数据的方式,在各个爬虫框架中也很多的使用到,具体的用法大致相同,细微之处可自行摸索。以下是最简单的一种方式。
1 | #! /usr/bin/python |
XPath是我在做爬虫任务时接触的,这只是整个环节中的一小部分,关于爬虫的一些抓取技巧(动态页面抓取、数据清洗、任务调度等)请关注博客后续更新的文章。
参考
http://www.cnblogs.com/barney/archive/2009/04/17/1438062.html
http://www.w3school.com.cn/xpath/xpath_functions.asp