深度学习系列第五篇 — 卷积神经网络
这篇例子是学习 莫烦PYTHON 视频教程整理的学习笔记。
卷积神经网络包含如下几层:
- 输入层
- 卷积层(卷积层的结构 + 向前传播算法) =>> (过滤器或内核)(用来提取特征,每一层会将图层变厚)
- 池化层(用来采样,稀疏参数,每一层会将图层变瘦)
- 全连接层(将前两层提取的图像特征使用全连接层完成分类任务)
- Softmax 层(主要处理分类,得到不同种类的概率分布情况)
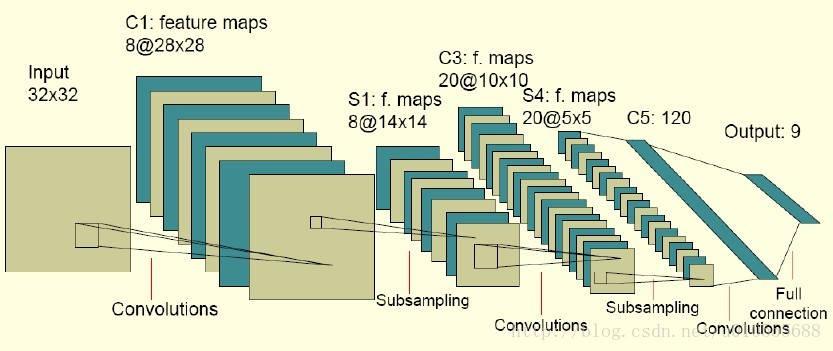
首先我们将如下包导入,这次练习是通过 Tensorflow 提供的 MNIST 数据集进行训练,识别手写数字。
1 | import tensorflow as tf |
Extracting MNIST_data/train-images-idx3-ubyte.gz
Extracting MNIST_data/train-labels-idx1-ubyte.gz
Extracting MNIST_data/t10k-images-idx3-ubyte.gz
Extracting MNIST_data/t10k-labels-idx1-ubyte.gz
1 | def weight_variable(shape): |
通过使用 softmax 分类器输出分类
1 | prediction = tf.nn.softmax(tf.matmul(h_fc1_drop, w_fc2) + b_fc2) |
loss函数(即最优化目标函数)选用交叉熵函数。交叉熵用来衡量预测值和真实值的相似程度,如果完全相同,它们的交叉熵等于零。
1 | cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction), reduction_indices=[1])) |
通过使用 AdamOptimizer 优化器进行优化,使 cross_entropy 最小
1 | train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy) |
下面开始训练,通过两千次的训练,每次抽样 100 条数据,每 100 次训练完验证一下预测的准确率
1 | with tf.Session() as sess: |
训练结果:
100 0.861
200 0.904
300 0.93
400 0.933
500 0.94
600 0.949
700 0.955
800 0.958
900 0.961
1000 0.964
1100 0.966
1200 0.968
1300 0.972
1400 0.968
1500 0.973
1600 0.972
1700 0.976
1800 0.975
1900 0.973
2000 0.981
end!