JVM GC
GC
- 引用计数算法,记录对象被引用的次数。
- 可达性分析算法,通过一系列的“GC Roots” 根对象作为开始节点集,根据引用关系向下搜索,如果某个对象到 GC Roots 间没有任何引用链相连,表明对象不可达。
引用的概念
- 强引用,普遍的引用赋值。
- 软引用,在程序将要内存溢出的时候可以进行回收,回收后内存依然不够时则抛出异常。
- 弱引用,生存周期为下一次垃圾回收为止。
- 虚引用,被垃圾回收时触发一次系统通知。
垃圾收集算法 - 分代收集理论
- 内存区域
- 新生代
- 老年代
- 永久代(元空间、方法区)
- 回收类型
- 新生代收集
- 老年代收集
- 整堆收集
- 回收算法
- 标记 - 清除算法:将垃圾对象标记清除。容易造成内存空间碎片化,大对象申请问题,可能触发下一次垃圾收集动作。
- 标记 - 复制算法:半区复制,浪费空间。新生代 eden 空间、两块 survivor 空间,比例是 8:1,每次只使用 Eden空间和一块survivor空间,进行垃圾回收时会将存活对象复制到另一块 survivor 空间,然后清理掉已经用过的 Eden 空间和 survivor 空间,这样整个新生代利用了 90% 的空间。当一次垃圾回收的存活对象超过一个surivor空间时会通过分配担保机制使用老年代空间。
- 标记 - 整理算法:清除后将所有存活对象向内存空间一端移动。
经典垃圾收集器
https://juejin.im/post/5e197cc0e51d451c774dc56f
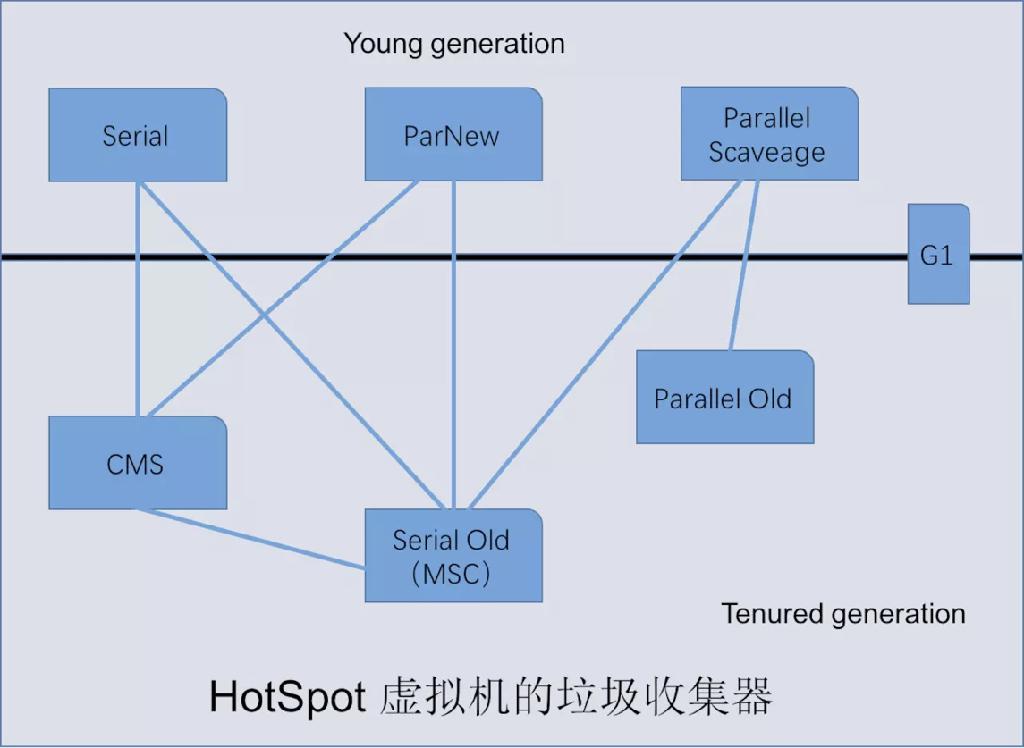
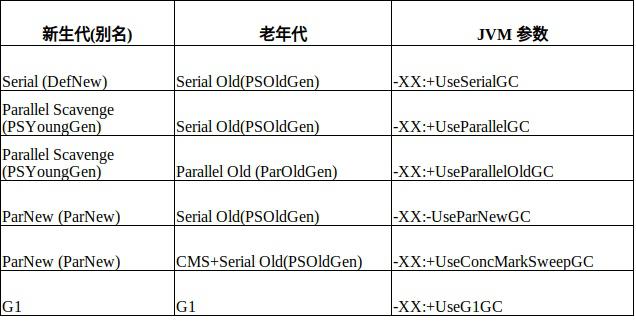
Java8 GC 默认使用的是 Parallel Scavenge (新生代) 和 Parallel Old (老年代)。
GC 日志
在启动命令中增加 -XX:+PrintGCDetails 输出详细GC日志。
1 | /** |
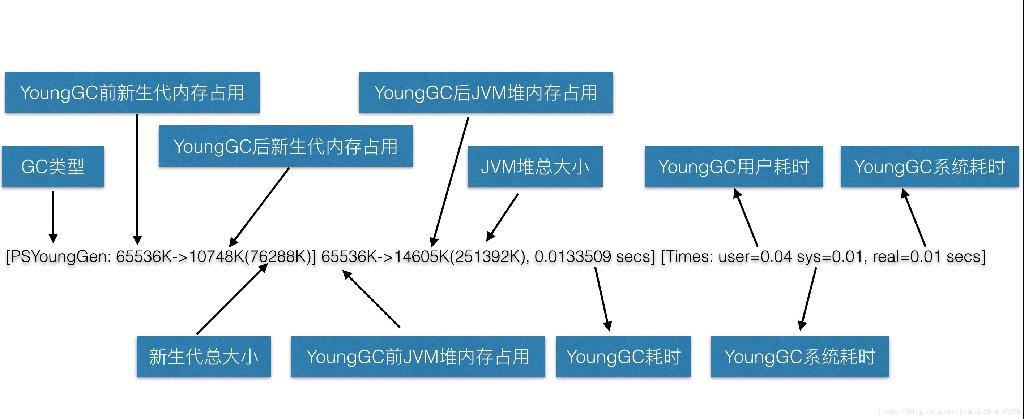
1 | [GC (Allocation Failure) [PSYoungGen: 8097K->1008K(9216K)] 11954K->10351K(19456K), 0.0091685 secs] [Times: user=0.02 sys=0.01, real=0.01 secs] |
GC:表明进行了一次垃圾回收,前面没有Full修饰,表明这是一次Minor GC ,注意它不表示只GC新生代,并且现有的不管是新生代还是老年代都会STW。 Allocation Failure:表明本次引起GC的原因是因为在年轻代中没有足够的空间能够存储新的数据了。
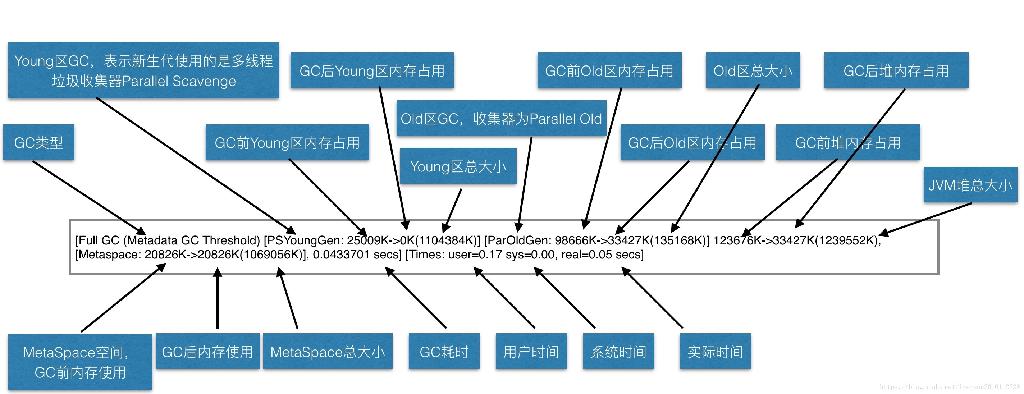
JVM
JVM 堆栈配置参数
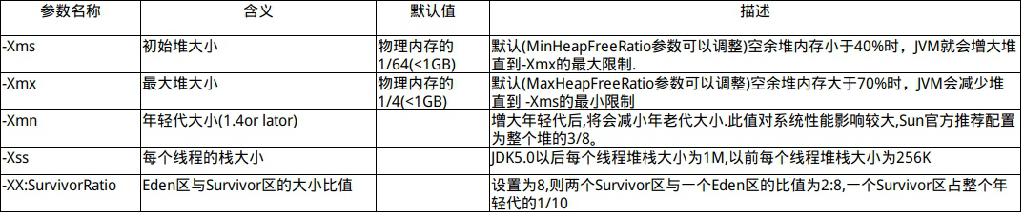
jps 查看 JVM 进程启动参数
默认元空间大小128M,最大元空间大小256M,初始化堆大小2G,最大堆大小5G,新生代512M,每个线程分配内存大小1M。eden空间和survivor空间的分配比率8:2,使用标记复制算法。
1 | root@xxx:/usr/lib/jvm/java-8-oracle/bin# ./jps -v |
jmap 生成堆快照
format 指定输出格式,live 指明是活着的对象,file 指定文件名。方便后面通过分析工具分析。
1 | jmap -dump:live,format=b,file=dump.hprof pid |
jstat 查看 JVM 进程已使用空间百分比

1 | root@xxx:/usr/lib/jvm/java-8-oracle/bin# ./jstat -gcutil 1 |
S0 survivo0
S1 survivo1
E Eden空间
O 老年代
M 元空间使用率
CCS 压缩使用比例
YGC 新生代 GC 次数
YGCT 新生代 GC 耗时
FGC Full GC 次数
FGCT Full GC 耗时
GCT GC 耗时
jmap 查看进程堆的详细信息
jmap -heap pid
1 | Attaching to process ID 3764, please wait... |
JVM调优
目的:对JVM内存的系统级的调优主要的目的是减少GC的频率和Full GC的次数,减少系统停顿时间。
步骤:
- 监控GC状态
- 生成 dump 文件
- 分析dump 文件(MAT 工具)
- 分析判断是否需要进行优化
- Minor GC执行时间超过50ms;
- Minor GC执行频繁,约10秒内一次;
- Full GC执行时间超过1s;
- Full GC执行频繁,高于10分钟1次;
- 调整GC类型和内存分配
- 不断分析调整