public static List<List<Integer>> threeSum(int[] nums) { List<List<Integer>> resp = new ArrayList<>(); Arrays.sort(nums); for (int i = 0; i < nums.length; i++) { if (nums[i] > 0) break; int l = i + 1; int r = nums.length - 1; if (i > 0 && nums[i-1] == nums[i]) continue; while (l < r){ int sum = nums[i] + nums[l] + nums[r]; if ( sum> 0) r--; else if (sum < 0) l++; else if (sum == 0){ resp.add(Arrays.asList(nums[i], nums[l] , nums[r])); while (l < r && nums[l] == nums[l+1]) l++; while (l < r && nums[r] == nums[r-1]) r--; l++; r--; } } } return resp; } }
public class GenerateParenthesis { public static void main(String[] args) { GenerateParenthesis obj = new GenerateParenthesis(); List<String> stringList = obj.generateParenthesis(3); System.out.println(stringList); }
public List<String> generateParenthesis(int n) { List<String> collect = new ArrayList<>(); gen(collect, "", n, n); return collect; }
public void gen(List<String> collect, String cur, int left, int right) { if (left == 0 && right == 0) { collect.add(cur); return; } if (left > 0) { gen(collect, cur + "(", left - 1, right); } if (right > 0 && right > left) { gen(collect, cur + ")", left, right - 1); } } }
49、242. 字母异位词
第一题:
242. 有效的字母异位词 给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。
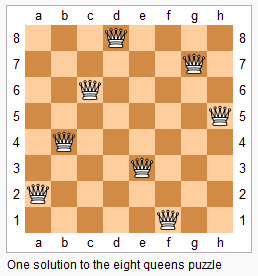
public class SolveNQueens { public static void main(String[] args) { SolveNQueens queens = new SolveNQueens(); System.out.println(queens.solveNQueens(5)); }
public List<List<String>> solveNQueens(int n) { List<List<String>> resp = new ArrayList<>(); Set<Integer> cols = new HashSet<>(); Set<Integer> pie = new HashSet<>(); Set<Integer> na = new HashSet<>(); dfs(n, 0, new ArrayList<>(), resp, cols, pie, na); return resp; }
public String trans(int point, int max) { char[] chars = new char[max]; for (int i = 0; i < max; i++) { chars[i] = i == point ? 'Q' : '.'; } return String.valueOf(chars); } }
public class MySqrt { public static void main(String[] args) { MySqrt mySqrt = new MySqrt(); System.out.println(mySqrt.mySqrt(2147395599));
}
// 边界问题 // 1. 0\1边界 // 类型长度越界 public int mySqrt(int x) { if (x == 0) return 0; if (x == 1) return 1; return mySqrt(x, 0, x); }
public int mySqrt(long x, long left, long right) { long cur = (right - left) / 2 + left; long cur2 = cur * cur; if (cur2 == x) { return (int) cur; } else if (right - left == 1) { return (int) left; }
if (cur2 < x) { left = cur; } else if (cur2 > x) { right = cur; } else { return (int) cur; } return mySqrt(x, left, right); } }
/** * Definition for a binary tree node. * public class TreeNode { * int val; * TreeNode left; * TreeNode right; * TreeNode(int x) { val = x; } * } */ class Solution { public boolean isValidBST(TreeNode root){ return forEachNode(root, new ArrayList<>()); }
public boolean forEachNode(TreeNode node, List<Integer> val){ if (null == node) { return true; } if (!forEachNode(node.left, val)){ return false; } if (!validOrAdd(val, node)){ return false; } if (!forEachNode(node.right, val)){ return false; } return true; } public boolean validOrAdd(List<Integer> val, TreeNode node){ if(val.size() > 0 && val.get(val.size() - 1) >= node.val){ return false; }else{ return val.add(node.val); } } }
/** * Definition for a binary tree node. * public class TreeNode { * int val; * TreeNode left; * TreeNode right; * TreeNode(int x) { val = x; } * } */ class Solution { public boolean isValidBST(TreeNode root){ return subValidBSTLeft(root, null, null); }
public boolean subValidBSTLeft(TreeNode node, Integer min, Integer max) { if (null == node){ return true; } if (null == min && null == max){ }else if (null == min && null !=max && node.val < max){ }else if (null != min && null == max && min < node.val){ }else if (null != min && null != max && min < node.val && node.val < max){ }else { return false; } // left if (!subValidBSTLeft(node.left, min, node.val)){ return false; } // right if (!subValidBSTLeft(node.right, node.val, max)){ return false; } return true; } }
102. 二叉树的层次遍历
问题
给定一个二叉树,返回其按层次遍历的节点值。 (即逐层地,从左到右访问所有节点)。
例如: 给定二叉树: [3,9,20,null,null,15,7],
1 2 3 4 5
3 / \ 9 20 / \ 15 7
返回其层次遍历结果:
1 2 3 4 5
[ [3], [9,20], [15,7] ]
解答
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
class Solution { public List<List<Integer>> levelOrder(TreeNode root) { List<List<Integer>> resp = new ArrayList<>(); levelOrder(root, 0, resp); return resp; } public void levelOrder(TreeNode cur, int cur_level, List<List<Integer>> resp) { if(null == cur){ return; } if(cur_level == resp.size()){ resp.add(new ArrayList<>()); } resp.get(cur_level).add(cur.val); levelOrder(cur.left, cur_level+1, resp); levelOrder(cur.right, cur_level+1, resp); } }
一次过
104. 二叉树的最大深度
问题
给定一个二叉树,找出其最大深度。
二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
说明: 叶子节点是指没有子节点的节点。
示例: 给定二叉树 [3,9,20,null,null,15,7],
1 2 3 4 5
3 / \ 9 20 / \ 15 7
返回它的最大深度 3 。
解答
1 2 3 4 5 6 7 8 9 10 11
class Solution { public int maxDepth(TreeNode root) { return maxDepth(root, 0); } public int maxDepth(TreeNode cur, int level) { if(null == cur) return level; int left_level = maxDepth(cur.left, level + 1); int right_level = maxDepth(cur.right, level + 1); return left_level > right_level ? left_level: right_level; } }
def get(self, key): """ :type key: int :rtype: int """ if key not in self._cache: return -1 val = self._cache.pop(key) self._cache[key] = val return val
def put(self, key, value): """ :type key: int :type value: int :rtype: None """ if key in self._cache: self._cache.pop(key) self._cache[key] = value else: if len(self._cache) == self._size: self._cache.popitem(last=False) self._cache[key] = value
# Your LRUCache object will be instantiated and called as such: # obj = LRUCache(capacity) # param_1 = obj.get(key) # obj.put(key,value)
xyz@xyz-pc:~$ sudo iptables -A OUTPUT -p tcp --syn --dport 12345 -j DROP xyz@xyz-pc:~$ curl --connect-timeout 10 "http://192.168.1.110:12345" curl: (28) Connection timed out after 10001 milliseconds
读取数据超时
1 2 3
xyz@xyz-pc:~$ sudo iptables -A OUTPUT -p tcp -m state --state ESTABLISHED --dport 12345 -j DROP xyz@xyz-pc:~$ curl --connect-timeout 10 -m 20 "http://192.168.1.110:12345" curl: (28) Operation timed out after 20001 milliseconds with 0 bytes received
拒绝连接
1 2 3
xyz@xyz-pc:~$ sudo iptables -A OUTPUT -p tcp --dport 12345 -j REJECT xyz@xyz-pc:~$ curl --connect-timeout 10 -m 20 "http://192.168.1.110:12345" curl: (7) Failed to connect to 192.168.1.110 port 12345: 拒绝连接
xyz-macdeMacBook-Pro:dev-demo xyz$ python mixin_demo.py Init people. People can eat! People can drink! People can Traceback (most recent call last): File "mixin_demo.py", line 44, in <module> people = People() File "mixin_demo.py", line 39, in __init__ print "People can ", self.sleep() File "mixin_demo.py", line 30, in sleep raise NotImplementedError(u"can't sleep.") NotImplementedError: can't sleep.
objc[20307]: Class JavaLaunchHelper is implemented in both /Library/Java/JavaVirtualMachines/jdk1.8.0_131.jdk/Contents/Home/bin/java (0x1077344c0) and /Library/Java/JavaVirtualMachines/jdk1.8.0_131.jdk/Contents/Home/jre/lib/libinstrument.dylib (0x10874d4e0). One of the two will be used. Which one is undefined. Exception in thread "main" org.springframework.beans.factory.NoSuchBeanDefinitionException: No bean named 'teacher2' available at org.springframework.beans.factory.support.DefaultListableBeanFactory.getBeanDefinition(DefaultListableBeanFactory.java:775) at org.springframework.beans.factory.support.AbstractBeanFactory.getMergedLocalBeanDefinition(AbstractBeanFactory.java:1221) at org.springframework.beans.factory.support.AbstractBeanFactory.doGetBean(AbstractBeanFactory.java:294) at org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:199) at org.springframework.beans.factory.support.CglibSubclassingInstantiationStrategy$LookupOverrideMethodInterceptor.intercept(CglibSubclassingInstantiationStrategy.java:290) at com.noogel.xyz.lookup.GetBeanTest$$EnhancerBySpringCGLIB$$e79f57a6.getBean(<generated>) at com.noogel.xyz.lookup.GetBeanTest.showMe(GetBeanTest.java:5) at LookupTestMain.main(LookupTestMain.java:9)
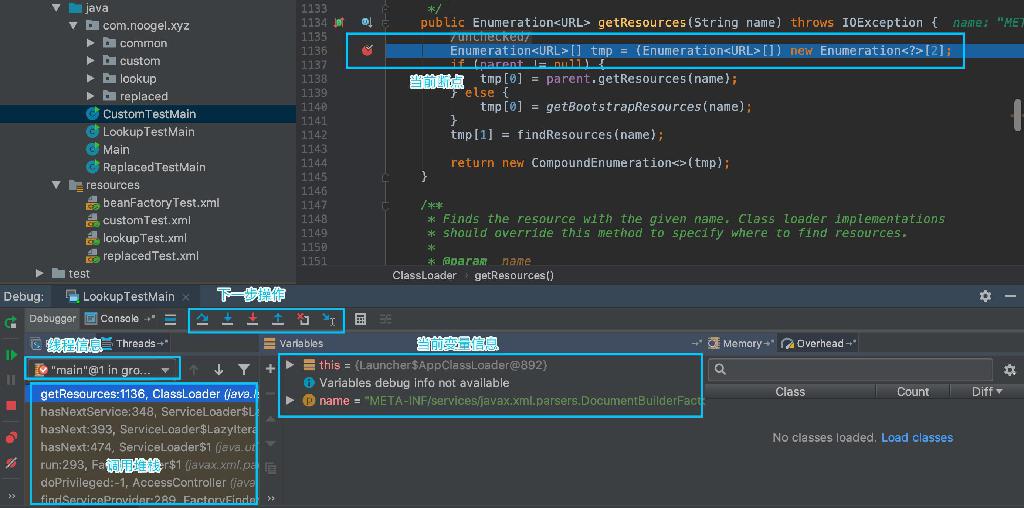
使用IDE断点调试
IDE 可以帮我们做很多事,大大提高了我们的开发效率,那么如何用好这样一个工具也是很关键的,这里说一下利用 IDE 进行 debug 调试。
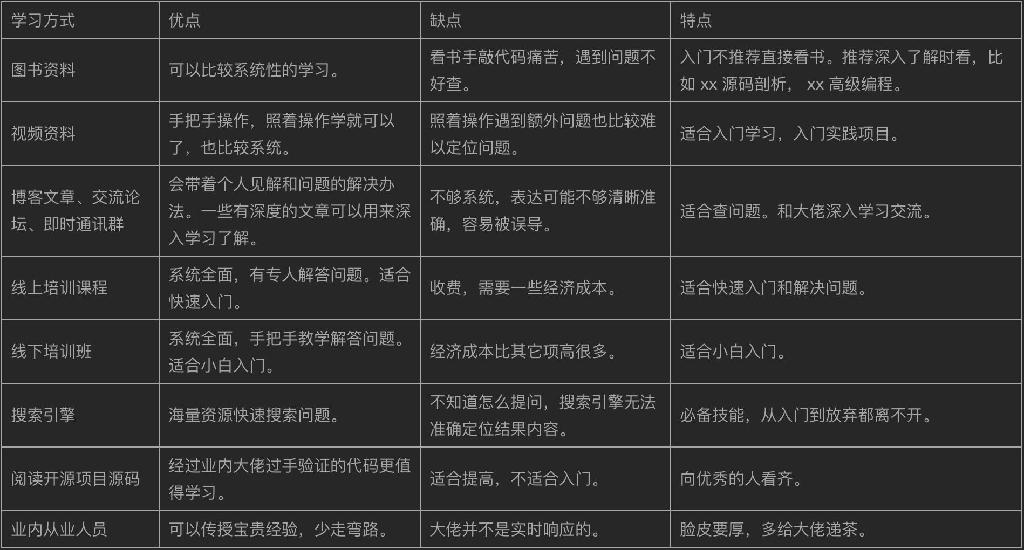
学习一门编程语言肯定是用来解决实际问题或找一份工作的,那么你要知道并不仅仅是学习这门编程语言,而是整个技术栈。了解一个语言的技术栈可以去招聘网站上看,一般都会写至少需要精通一门编程语言,熟练使用 MySQL 解决并优化问题,熟练使用并了解各种 MQ 原理等等。那么这些都是需要去了解的,起初学习可以为了用而用的去实践一个更完整的需求。